

What is the CampusCluster?
The CampusCluster is a link between many different servers maintained by various colleges, departments, labs and individuals at the University of Illinois at Urbana-Champaign. The central idea is as follows: Many different groups need server cycles, but most of them don’t always need that much power. In fact, most of the time those servers are inactive! The campuscluster is a server network that not only allows users to run programs on their own servers, but also allows users to request cycles from other people’s inactive servers.
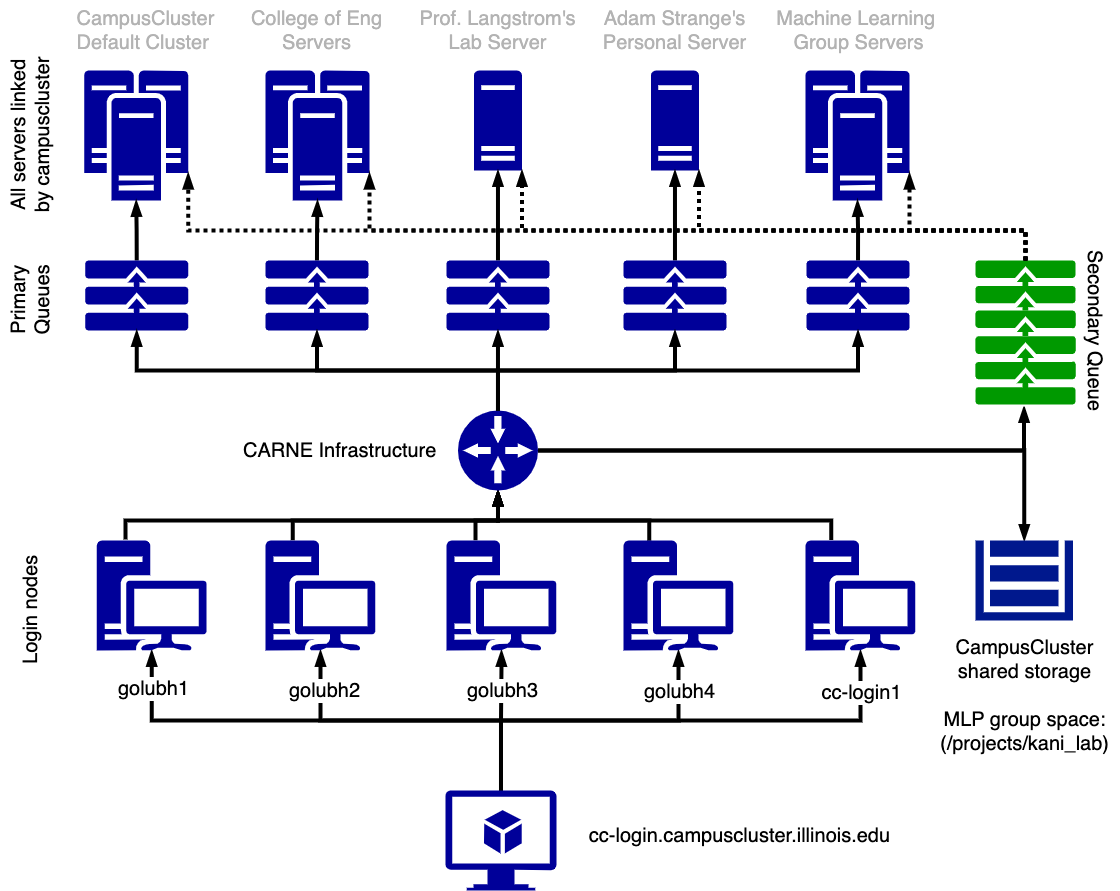
Using the Campus Cluster (CC) is a unique experience because up until now, you’ve probably used classic computer architectures where you remote into a server, run your program and logout. However, managing the number of users and machines that the CC has requires individuals adopt a new process where you submit jobs (program runs) to a queue and wait for the server to get free, run the job, and notify you once it is done.
Big idea for using the CC: you submit jobs to queues not servers. So instead of telling the server that you are logged into to run prog.exe, you instead have to tell a queue that you want a server with XYZ hardware to run prog.exe. The queue will wait until the server has completed the jobs before you to send it your job.
Each server is connected to two types of queues, a primary and secondary. The primary queue is specific to that server and access is typically limited to the individuals/groups that own that server. The server itself prioritizes taking jobs from the primary queue basically giving its owners dibs on the server time. This gives groups an incentive to buy and connect servers to the CC since their server will always prioritize their work.
The secondary queue is what allow the Illinois community to share unused server cycles. If a server’s primary queue is empty, the server will look at the secondary queue and see if there are any jobs it can perform (accounting for hardware requirements and such). If there are, the server will pick up that job and complete it. Anyone may submit a job to the secondary queue allowing even those individuals without equipment/funding some level of support. However, note that the secondary queue is usually very busy and wait times can be long. For this reason, it is always preferable to get access to as many primary queues as you can.
Getting Started
Logging in
To log into the campus cluster, open your terminal and ssh in with this command:
ssh yournetid@cc-login.campuscluster.illinois.eduLoading software
Next, use ‘module’ to load the software packages you will use. Some common software packages you might want to use include python3, nano, and anaconda.
To load a package, run:
module load python/3For a full list of available packages on the campus cluster, run:
module listUpdating your .bashrc file
Loading important software every session can be annoying. Fortunately, you have a .bashrc script. A .bashrc script is a bash script that runs automatically when you log into a new session. If you include your module load statements in this file, your environment will be ready for you when you sign in.
To edit your .bashsc file, run:
module load nano
nano $HOME/.bashrcBelow is a sample .bashrc file.
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions
module load nano
module load python/3
module load anaconda/2021-May/3
cd /projects/kani-lab/user/yournetidUploading files to and from the campus cluster
There are several ways to upload and download files on the campus cluster. The first way is from your terminal, using scp. To upload a file to a directory on the campus cluster with scp, run:
scp yourfile.txt yournetid@cc-login.campuscluster.illinois.edu:/projects/kani-lab/user/yournetid/yourfolderTo download a file to your local computer from the campus cluster, run:
scp yournetid@cc-login.campuscluster.illinois.edu:/projects/kani-lab/user/yournetid/yourfile.txt yourfile.txtAdditionally, you can use third-party file-sharing software, like FileZilla (though it requires a paid subscription). On Windows, WinSCP is pretty much perfect and free. On OSX, there’s CyberDuck which is free but I had some issues last I used it so I just paid for FileZilla.
Submitting a Job
Let’s say you want to run a python script on the campus cluster. To do this, you will submit a job to one of the queues via a .pbs file. Queues are the way jobs are run on the campus cluster. Queues on the campus cluster operate just like the queues in your data structures class; the first job in, first job out. Each queue has different resources such as execution time and processors. The queues subsection highlights some of the queues you might want to use to run your jobs.
.pbs files are specialized bash scripts that tell the queue how to run your job. Below is a sample bash script.
#!/bin/sh
#PBS -M yournetid@illinois.edu # you will be emailed with updates about your jobs
#PBS -N name of the job
#PBS -l walltime=48:00:00 # how long you want your job to run
#PBS -l nodes=1
#PBS -m a # this argument specifies when the campus cluster will email you about the status of your job. n=no mail, a=job aborts b=job begins and e=job ends
#PBS -q csl # the queue that you are running the job on
# your code hereTo submit a bash script, run:
qsub yourfile.pbsThis will generate a job id number. If you want to delete it from the queue, run:
qdel jobidnumberYou can also delete multiple jobs from the queue whose job id numbers are in sequential order. For example, if you have 3 jobs with id numbers 1 2, and 3, you would run the following command to delete all of them at once:
qdel {1..3}If you want to see if your jobs are running, run:
qstat -u yournetidWhen a job runs, two output files will be generated: an error file and an output file. Error files contain any errors or error logs that occurred during the execution of your script. Output files contain any output logs or print statements that occurred during execution.
There are a few considerations when running a job:
- Queues run the code of the .pbs file at the time of submission. If you submit a job and then change the .pbs file you used to submit that job, that change will not be reflected and the older version of the file will be executed. However, if you submit a job and then change a file that you run from the .pbs file, the new version of that file will be executed.
- When using a conda environment, be sure to submit your job while you are in the correct conda environment. If you submit a job while not in the correct environment, some of the packages needed to run your code will not be available and your job will fail.
Queues
There are two types of queues:
- primary - This is a server specific queue which gets priority. Access is limited but if you know the administrator you can ask for access using this form.
- secondary - This queue is available for everyone to run on. It’s limited to machines with a CPU processor and has a maximum runtime of 4 hours.
On campus there are several large groups that have servers available for their members. You can ask for access using this form. Some notable queues our group uses frequently are:
- csl - This is a queue that you need to apply for, but the resources are much better than the secondary queue. The maximum runtime is 7 days (168 hours) and it uses a cpu processor.
- eng-research-gpu - If your job requires a GPU to run, you would submit it to this queue. There are four types of GPUs on this queue: Tesla M2090, Tesla K40M, Tesla K80, and P100. This queue has a maximum runtime of two days (48 hours) and requires an application to access. To submit a .pbs file on eng-research-gpu, some extra information needs to be added to the header. Below is a sample .pbs file for the eng-research-gpu queue.
#!/bin/sh
#PBS -M yournetid@illinois.edu
#PBS -N name of the job
#PBS -l walltime=48:00:00
#PBS -l nodes=1
#PBS -m a
#PBS -q eng-research-gpu
#SBATCH --gres gpu:V100 # specify which GPU type
#SBATCH --ntasks-per-node=32 # specify number of cores
# your code hereRunning Interactive Jobs
One thing that’s kinda cool is that if you need a program to run for longer than 20minutes but don’t want to write a script to submit a job, you can start an interactive job.
All you need is one simple command
srun --partition=eng-research-gpu --time=48:00:00 --nodes=1 --ntasks-per-node=4 --cpus-per-task=8 --gres=gpu:A10:4 --pty /bin/bashRemember that if you do this on your terminal, when you close the terminal you’ll also stop the interactive job. To avoid this, you can use the screen command.
Kinda cool hack. Huge thanks to Sumedh for showing it to me!
References
- Campus cluster user guide - https://campuscluster.illinois.edu/resources/docs/user-guide/
- Using pip on the campus cluster - https://campuscluster.illinois.edu/python-on-the-campus-cluster/
- Guide to .pbs files - https://www.chpc.utah.edu/documentation/software/pbs-scheduler.php